一.基本命令
1.新建一个django project
django-admin.py startproject project_name特别是在windows上如果报错,尝试使用django-admin代替django-admin.py
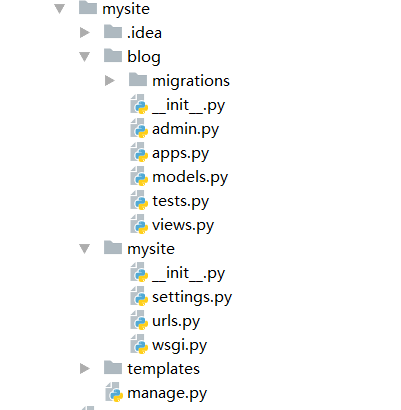
2.新建app
新建app需要切换到项目目录project_name下,即 cd project_name然后:python manage.py startapp app_name或django-admin.py startapp app_name
3.创建数据库表或更改数据库表或字段
Django 1.7.1及以上1.创建更改的文件python manage.py makemigrations2.将生成的py文件应用到数据库python manage.py migrate旧版本Django1.6及以下python manage.py syncdb
这种方法可以在SQL等数据库中创建与models.py代码对应的表,不需要自己手动执行SQL
4.使用开发服务器
开发服务器,一般修改代码后会自动重启,方便调试和开发,但是由于性能问题,建议只用在测试,不可用在生产环境
python manage.py runserver IP:PORT
5.清空数据库
python manage.py flush
6.创建超级管理员
python manage.py create superuser修改用户密码python manage.py changepassword username
7.导出数据 导入数据
python manage.py dumpdata appname > appname.jsonpython manage.py loaddata appname.json
8.Django项目环境终端
python manage.py shell
如果安装了bpython或ipython会自动调用它们的界面
这个命令和直接运行python或bpython进入shell的区别:可以在这个shell中调用当前项目的models.py中的API,对于操作数据和小测试都非常方便
9.数据库命令行
python manage.py dbshell
Django会自动进入settings.py中设置的数据库,如果是MySQL或postgreSQL,则会要求输入数据库用户密码
10.更多命令
python manage.py
查看详细的命令列表
11.static静态文件配置
每个应用都需要配置static静态文件,在每个应用的目录下创建static文件夹,将每个应用所需的静态文件放在里面,在settings中加入STATIC_ROOT=( os.path.join(BASE_DIR, "app_name/static"))
{% load staticfiles %}#
二.视图与网址
Django中网址写在urls.py文件中,用正则表达式对应view.py中的一个函数或者generic类
2.1定义视图函数
from django.shortcuts import render
def index(request): return render(request,'index.html')
定义一个index函数,第一个参数必须是request,与网页发来的请求有关,request变量中包含get或post的内容,用户浏览器,系统等信息在里面
2.2定义视图函数相关的URL网址,打开project_name/project_name/urls.py文件
from django.conf.urls import url,includefrom django.contrib import adminfrom blog import viewsurlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^$',views.index), url(r'^index/',views.index), # url(r'^(\d{4})/$',year_query) 如果想要获取匹配的值并传入后边的视图函数,可以把想要匹配的正则表达式加上括号,成为后边的视图函数的参数,并以位置参数的形式传入 # url(r'^(?P \d{4})/(?P \d{2})$',views.year_query), 命名传入参数,以关键字参数传入 # url(r'reg/',views.reg,name="register") url(r'^blog/',include('blog.urls')) #新的应用需要添加对应的urls避免耦合,通过import include,并以该种形式实现对应应用的路由] 路由分配系统
功能:客服端访问的url的路径(path)与视图函数一一映射关系
语法格式:
urlpatterns = [
url(正则表达式,views视图函数,参数,别名
]
key: 通过路径分组传参数给视图函数
向server端传参数方式:
(1)通过数据:http://1277.0.0.1:8080/blog/?id=1200
(2)通过路径:http://1277.0.0.1:8080/blog/1200
url(r"blog/(\d{4})")
2.3URL中的name
url(r'^reg/',views.reg,name="register")
简单说,name可以用于在templates,models,views……中得到对应的网址,相当于给网址取了个名字,只要名字不变,网址变了也能通过名字获得
我们注册页面用的是/reg/,如果以后网址进行了变更,比如改成了/new_client/,但在网页中,代码中很多地方都是写死的/reg/,如果是这样把网站写死了,会在更改了网址(正则)后,模板(templates),视图(views.py用于跳转),模型(models.py,获取对象对应的地址)用了此网址的,都需要进行相应的更改,十分繁琐
如果网址修改成了/new_client/,即urls.py进行了更改获取的网址也会动态地跟着改变,但是后面的name='register'没有改变,这时{%url 'register' %}就会渲染对应的网址成/new_client/
三.快捷函数
def login(request): if request.method=="POST": username=request.POST.get("username") pwd=request.POST.get("pwd") if username=='xiaobai' and pwd=='123': return redirect('/index/') return render(request, "login.html")#总结: render和redirect的区别:# 1 if render的页面需要模板语言渲染,需要的将数据库的数据加载到html,那么所有的这一部分# 除了写在yuan_back的视图函数中,必须还要写在login中,代码重复,没有解耦.# 2 the most important: url没有跳转到/yuan_back/,而是还在/login/,所以当刷新后# 又得重新登录. 四. Template
使用大括号来引用变量
{
{ a.1 }}{
{ a.0 }}
{ % for person in querySet %} { { person.name }}{ % endfor %}
{ % if i > 50 %} { { i }}{ %else %}50
{ % endif %}==================def index(request): i=65 a=[11,22,33,44] d={ "name":"xiaobai","age":22} class Person(object): def __init__(self,name): self.name=name p1=Person("xiaobai") p2=Person("xiaohei") p3=Person("xiaoming") querySet=[p1,p2,p3] return render(request,"index.html",locals())
五.创建模型models
1.新建项目和应用django-admin.py startproject BookManagecd BookManagepython manage.py startapp Book2.添加应用将新建的应用Book添加到settings.py中的INSTALLED_APPS中INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'Book',)3.修改models.pyclass Book(models.Model): title=models.CharField(max_length=32) price=models.IntegerField() date=models.DateField() publish=models.CharField(max_length=32) author=models.CharField(max_length=32)新建一个Book类,继承models.Model4.创建数据表,使用SQLite3cd BookManagepython manage.py makemigrationspython manage.py migrate
六.标签的使用
{% if %}的使用
{% if i > 50 %} { { i }}{ %else %} 50
{ % endif %} ============== {% if %} 标签接受and,or或者not来测试多个变量值或者否定一个给定的变量{% if %} 标签不允许同一标签里同时出现and和or,否则逻辑容易产生歧义,例如下面的标签是不合法的:{% if obj1 and obj2 or obj3 %} {% for %}的使用
- { % for obj in list %}
- { { obj.name }} { % endfor %}
#在标签里添加reversed来反序循环列表: { % for obj in list reversed %} ... { % endfor %}#{% for %}标签可以嵌套: { % for country in countries %} { { country.name }}
- { % for city in country.city_list %}
- { { city }} { % endfor %}
{
{ forloop.counter }}: { { item }} { % endfor %}2,forloop.counter0 类似于forloop.counter,但它是从0开始计数,第一次循环设为03,forloop.revcounter4,forloop.revcounter05,forloop.first当第一次循环时值为True,在特别情况下很有用: { % for object in objects %} { % if forloop.first %}{% url %}引用配置的路由,与name方法连用
6.1 加载标签库:自定义filter和simple_tag
6.1.1在应用目录下创建templatetags目录
6.1.2在templatetags目录下创建.py文件,如Mytag.py
语法格式: { {obj|filter:param}} # 1 add : 给变量加上相应的值 # # 2 addslashes : 给变量中的引号前加上斜线 # # 3 capfirst : 首字母大写 # # 4 cut : 从字符串中移除指定的字符 # # 5 date : 格式化日期字符串 # # 6 default : 如果值是False,就替换成设置的默认值,否则就是用本来的值 # # 7 default_if_none: 如果值是None,就替换成设置的默认值,否则就使用本来的值 from django import templateregister=template.Library() #register名字是固定的,不能任意定义@register.filterdef multi(x,y): return x * y@register.simple_tagdef multi_argu(x,y,z): return x * y * z
6.1.3在使用定义了simple_tag和filter的html文件中加载之前创建的Mytag.py:{% load Mytag%}
6.1.3使用simple_tag和filter


{ { d|date:"Y-m-d" }}
{ { w|truncatechars:5 }}
{ { w|truncatewords:5 }}
{ { s|default:"此处为空" }}
{ { i|multi:5 }}
{% multi_argu 4 5 6 %}
=========================def index(request): i=10 w="sadasljdlasjdlajsldajsljalsjldjasljdalsjljalsjldajskjad" d=datetime.datetime.now() s="" return render(request,"index.html",locals())
七.模板继承
在网站中,为了减少共用页面区域的重复和冗余代码,如导航,底部,访问统计代码等,Django提供了模板继承extend方法。模板集成就是先构造一个基础框架模板,而后在其子模板中对它所包含站点公用部分和定义块进行重载。
下面是base.html 和 index.html
"base.html"Title ======================================={ % extends "base.html" %}{ % block con %} { { block.super }} { # 继承con的所有内容并添加以下内容到con内容之后 #}
- 菜单一
- 菜单二
- 菜单三
{ % block con %}bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
bai
{ % endblock %} { % block page %}PAGE
{ % endblock %}xiao
xiao
xiao
xiao
xiao
xiao
xiao
xiao
{ % endblock %}{ % block page %}This is page
{ % endblock %}{ % include "add.html" %}
八.数据库
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

更改MySQL配置修改如下
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'books', #你的数据库名称 'USER': 'root', #你的数据库用户名 'PASSWORD': '', #你的数据库密码 'HOST': '', #你的数据库主机,留空默认为localhost 'PORT': '3306', #你的数据库端口 }} 注意:
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建USER和PASSWORD分别是数据库的用户名和密码。设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。然后,启动项目,会报错:no module named MySQLdb这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL所以,我们只需要找到项目名文件下的__init__,在里面写入:import pymysqlpymysql.install_as_MySQLdb()
九.ORM模型
模型之间的三种关系:一对一,一对多,多对多
一对一:在主外键的关系基础上,给外键添加一个UNIQUE=True的属性
一对多:就是主外键关系 foreign key
多对多:(ManyToManyField)自动创建第三张表,也可以自己创建第三张表
9.1 ORM 增加表记录
from app01.models import * #create方式一: Author.objects.create(name='Alvin') #create方式二: Author.objects.create(**{"name":"alex"}) #save方式一: author=Author(name="alvin") author.save() #save方式二: author=Author() author.name="alvin" author.save() 一对多(ForeignKey):
# 一对多的记录创建方式 # 方法一 # Book.objects.create( # title="小白的帅气是如何炼成的", # price=999.99, # publish_id=1 # # ) # 方法二 # publish_obj=Publish.objects.get(id=2) # Book.objects.create( # title="小白的英俊是如何炼成的", # price=999.99, # publish=publish_obj # # )
多对多 (ManyToManyField)
author1=Author.objects.get(id=1) author2=Author.objects.filter(name='alvin')[0] book=Book.objects.get(id=1) book.authors.add(author1,author2) #等同于: book.authors.add(*[author1,author2]) book.authors.remove(*[author1,author2]) #------------------- book=models.Book.objects.filter(id__gt=1) authors=models.Author.objects.filter(id=1)[0] authors.book_set.add(*book) authors.book_set.remove(*book) #------------------- book.authors.add(1) book.authors.remove(1) authors.book_set.add(1) authors.book_set.remove(1)#注意: 如果第三张表是通过models.ManyToManyField()自动创建的,那么绑定关系只有上面一种方式# 如果第三张表是自己创建的:class Book2Author(models.Model): author=models.ForeignKey("Author") Book= models.ForeignKey("Book")# 那么就还有一种方式: author_obj=models.Author.objects.filter(id=2).first() book_obj =models.Book.objects.filter(id=3).first() s=models.Book2Author.objects.create(author_id=1,Book_id=2) s.save() s=models.Book2Author(author=author_obj,Book_id=1) s.save() 9.2 ORM 删除表记录
Book.objects.filter(id=1).delete()
9.3 ORM修改表记录
Book.objects.filter(id=3).update(title="PHP")#--------------- save方法会将所有属性重新设定一遍,效率低----------- obj=Book.objects.filter(id=3)[0] obj.title="Python" obj.save()
想要显示对应的SQL语句,需要在settings加上日志记录配置
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, }} 9.4 ORM查询表记录
# 查询相关API:# <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象# <2>all(): 查询所有结果# <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。#-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()--------# <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象# <6>order_by(*field): 对查询结果排序# <7>reverse(): 对查询结果反向排序# <8>distinct(): 从返回结果中剔除重复纪录# <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列# <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。# <11>first(): 返回第一条记录# <12>last(): 返回最后一条记录# <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False
# ret=Book.objects.values("title") # # print(ret) # ret=Book.objects.values_list("title","price") # # print(ret) # ret=Book.objects.exclude(id=1) # print(ret) # book_list=Book.objects.all().iterator() #将查找对象转换为迭代器,节省资源 # for book in book_lis 单表 的 表记录查询# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值## models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in## models.Tb1.objects.filter(name__contains="ven")# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感## models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and## startswith,istartswith, endswith, iendswith,
9.5 单表正向查询和反向查询
# 正向查找 # book_obj=Book.objects.filter(id=1).first() # print(book_obj.publish.name) #人民出版社 # book_obj=Book.objects.filter(id=2).first() # author_list=book_obj.authors.all() # for author in author_list: # print(author.name) # 反向查找 # pub=Publish.objects.get(name="人民出版社") # ret=pub.book_set.all().values("title") # print(ret) 9.6 多表条件关联正向和反向查询
#正向查找#一对多ret=Book.objects.filter(title="python").values.("publish__addr")##[{'publish__addr': '北京'}]#查询书名python的出版社地址#多对多ret=Book.objects.filter(title="python").values("author__name")ret=Book.objects.filter(author__name="xiaobai").values("title")#查询书名为python的作者名字#反向查找ret=Author.objects.filter(book__title="python").values("name") 十.聚合查询和分组查询
10.1 aggregate
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成集合
from django.db.models import Avg,Min,Sum,MaxBook.objects.all().aggregate(Avg("price"))#查询所有图书的平均价格aggregate()是QuerySet的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值得标识符,值是计算而来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果想要指定一个名称,可以向聚合子句提供:Book.objects.aggregate(average_price=Avg("price") 10.2 annotate
通过计算查询结果中每一个对象所关联的对象集合,从而计算出总值,即为查询集的每一项生成聚合
Book.objects.filter(author__name="xiaobai").values("title")#查询作为为xiaobai写的所有书Book.objects.filter(authors__name="xiaobai").aggregate(Sum("price"))#查询xiaobai所有书的价格#查询每个作者所写书的总价格涉及到分组Book.objects.values("author__name"").annotate(Sum("price"))#查询各个出版社价格最低的书Book.objects.vaues("publish__name").annotate(Min("price"))#[{"publish__name":"北大出版社","price__min":Decimal("10.00")},{ "publish__name":"人民出版社","price__min":Decimal("20.00")},{ "publish__name":"河北出版社","price__min":Decimal("30.00")},] 10.3 F查询和Q查询
from django.db.models import F,Q#F使用查询条件的值,专门取对象中某列值的操作Book.objects.all().update(price=F("price")+20)#Q构建检索条件Book.objects.filter(Q(price__gt=200) | Q(id__gt=5) , Q(title__startswith="小"))以小开头的价格或者ID大于5的书#Q可以对关键字参数进行封装,从而应用多个条件查询# 可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。 Q(title__startswith='P') | Q(title__startswith='J') # Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合 Q(title__startswith='P') | ~Q(pub_date__year=2005)